ソフトウェア品質向上のために 〜HISコードメトリクス〜
結構前に、以下のようなツイートをしました
「if-else ifに対しては条件抜けがないことを明示するために書く」ってのがIPAが出してる組み込みソフトコーディングガイドに記載されてるので、それに準拠してるとこは書くかも https://t.co/Vdb7QZJXGt
— じっく (@zickuuu) 2022年1月8日
引用元ツイートはそこそこリプや引用もされてて、地味に(自分の中で)話題になっていたのですが、おそらく携わる業界によってかなり文化が異なるんだなあと改めて実感した事例です。
ツイートはMISRA-C 2012というC言語用のコーディングガイドラインが発端のものですが、組み込み系(特に高い品質が求められる製品)ではこれに限らず、さまざまな規約・ルール・要求等があります。ソフトウェア工学や統計的な観点から生まれたもの、エキスパート数名や何らかの組織から発足したものまで様々ですが、中には古い慣習から続けられているものもあります。
ここではそれらについて考え直す意図も含めて、車載ソフト開発の現場でソフトウェア品質向上のためにどのような方策がとられているか・その背景的なところを振り返ってみます。他業界よりも高信頼性が求められる傾向にある車載業界で実際に適用されている方法論はどんなものがあるか、といったことが知りたい人への参考になればよいかなと。
「そもそも品質とは何か」みたいな話はwikiなどを見るとわかりやすいかもです。
なお品質向上には開発プロセスのような抽象的アプローチから、「設計上のアンチパターンを回避する」といった具象・実装よりなアプローチなど様々な手段がとられますが、実装に近いほどイメージが沸きやすいため、そこから始めてみます。というわけでコードメトリクスについて考えていく。
- コードメトリクスとは?
- 主な指標
- プロジェクトスコープ
- ファイルスコープ
- 関数スコープ
- 循環的複雑度/経路複雑度 (Cyclomatic Complexity)
- パスの数 (Number of Paths)
- 呼び出しレベルの数 (Number of Call Levels)
- 呼び出し元関数の数 (Number of Calling Functions)
- 呼び出された関数の数 (Number of Called Functions)
- 関数パラメータの数 (Number of Function Parameters)
- gotoステートメントの数 (Number of Goto Statements)
- 命令の (Number of Instructions)
- returnステートメントの数 (Number of Return Statements)
- 言語スコープ (Language Scope)
- 終わりに
コードメトリクスとは?
品質担保の代表格、おおよそどの言語・プロジェクトにも適用しうる指標です。設計や実装の「良さ」を定量化したものとも言えます。レビュー観点として策定してしまえば、ある種機械的に合否を判断できる分、導入のハードルは低いです。
コードメトリクスは主に静的解析ツールで算出することができます(IDEで算出できるものもある)。ここではコードメトリクスの中でも、Hersteller Initiative Software(HIS)1で推奨されているメトリクスについて触れます。
主な指標
HISコードメトリクスはその対象範囲に合わせて、大きく3つのスコープに分類できます。
- プロジェクトスコープ
- ファイルスコープ
- 関数スコープ
プロジェクトスコープ
直接再帰の数 (Number of Direct Recursions)
いわゆる自己再帰関数の数です。この指標の推奨値は0です。
自分はECU開発ぐらいしか製品ソフトの開発経験がないので「どうしても再帰じゃないと困る」場面があまり思いつきませんが、仮に使用する場合は厳密に制御された上で使用する必要があります。再帰関数の使用で発生しそうな問題は
- スタックを大量消費する
- 複雑で動作イメージがわきにくい(保守コスト大)
- 使い所を見極めないと単純な
forよりも効率が著しく悪くなる - テストが困難
くらいでしょうか。特に車載部品が複雑化する昨今ではソフトウェアのサプライチェーンが長くなり、様々な知識・経験レベルの人間が関わることを想定2して開発しなければならないため、上記リスクを許容してまで再帰関数を採用する動機はほぼないでしょう。(あったらこっそり教えてください)
再帰の数 (Number of Recursions)
再帰には上記の直接再帰の他に、「間接再帰」と言うものもあります。二つの関数が互いにコールしあっているような場合ですね。この指標では、関数を頂点、コール関係を辺とした有向グラフを描いたとき、全ての頂点から他の任意の頂点に移動できるパスが存在するような頂点の集合を「強連結要素」と定義し、
- 直接再帰の数
- 強連結要素の数
の合計を計測します。
例えば以下のfunc1, func2, func3は、どの関数を始点としても任意の関数に到達できるため、強連結要素とみなされます。
int func1(){ if (a){ func2(); }else{ func3(); } } int func2(){ func1(); } int func3(){ if (b){ func1(); } }
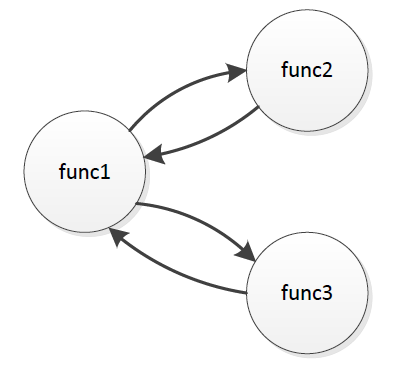
強連結要素はいくつの関数で構成されていても1と数えます。この指標の推奨値は0です。
そもそも普通に作ってたらそうはならんやろ…と言いたくなりますが、なにか特別なケースだとこういう設計の方が嬉しいことがあるんでしょうか。よくわからん。
ファイルスコープ
コメント密度 (Comment Density)
文字通りコメントの密度です。対象となるファイル内のステートメントとコメントの数の比率を計測します。以下の基準に従って、ステートメントとコメントの数を計算します。
コメント数 / ステートメント数 * 100 でコメント密度を算出します。この指標の推奨値は20以上です。(コード例を出して手計算するのがまあまあめんどくさいので割愛)
推奨値を達成するためにはおおよそ5ステートメントに1コメント書く必要があるわけですが、この量が多いか少ないかは賛否が分かれそうですね。コメントには冗長な情報を書くべきではないため3、ただこの推奨値を満足させるためにコメントを書くと可読性には逆効果となるためです。その辺のリテラシーが開発者には求められるでしょう。
この指標のミソは「複数行連続するコメントは1つとして数える」、「ソースで始まる行のコメントは無視」というところにあると思います。つまり
- できるだけ細かい単位でコメントを書くように促している
- 一行のみを修飾するようなコメントはカウントしない
というふうにメトリクスが作られています。「aにbを代入する」みたいな無意味なコメントを省きつつ、処理単位での設計意図や背景を書かせるようにしているものと予想されます。ソースコードではなくコメントに対して、実用に耐えうる指標を設けているのはなかなか興味深いと個人的には思いました。ただやはり指標だけハックしようと思えばいくらでもコメント量産されてしまうので、ある程度リテラシーは求められるかも…。頑張って意味のあるコメント書こうね。
関数スコープ
循環的複雑度/経路複雑度 (Cyclomatic Complexity)
関数内の判定点の数によって計算されます。ここでいう判定点とは制御フローが2つに分岐する点のことであり、
iffor,while(条件式が評価されない場合もカウント)switch-caseの、breakを含むcase- 三項演算子
?:
を判定点と呼びます。(ただし、&& , ||によるbooleanの結合は判定点として数えない)
判定点数の和に+1したものがその関数の循環的複雑度です。判定点が0の関数の循環的複雑度は1となります。
例えば、以下の関数func()の循環的複雑度は6です。
int func(){ if(A){ // +1 d = (a ? b : c); // +1 }else if(B || C){ // +1 // 処理 }else{ while(D){ // +1 swhitch(E){ case 1: case 2: // 処理 break; // +1 default: // 処理 } } } }
循環的複雑度は10以下が推奨となっています。
言われなくてもなんとなくわかりそうですが、判定点が多いとそれだけ可読性が悪化し、テストケース設計が困難になります。また「その関数内で多様な判断をしている」と考えると、凝集度が低くなっている可能性があります。比較的計測しやすく、設計見直しの指標としてもそれなりに効果的なので気にして損はないと言えそうです。
経路複雑度とも呼ばれ、これを拡張した指標4もあります。
パスの数 (Number of Paths)
その関数内で実行しうる静的経路数です。path coverage5を100%にするために必要なテストケース数と同じです。循環的複雑度と同じく、
iffor,while(条件評価に関わらず)switch-caseの、breakを含むcase
によって各制御フロー6の経路数が決まります(ただし、三項演算子?:は制御フローを中断しないとみなす)。入れ子になっている場合は単純な経路数の和ですが、独立した制御フローが複数存在する場合はそれぞれの積を取ります。
例えば、以下の関数func()のパスの数は6です。
int func(){ if(A){ // この制御フローの経路数は2 // 処理 } if (B){ // この制御フローの経路数は3 while(C){ // 処理 } } return (a ? b : c); // no count // パスの数 = 2 * 3 = 6 }
パスの数の推奨値は80以下です。
独立したifの数だけ累乗で増えていくため、関数やコンポーネントの責務によっては巨大な数となることもありえます。組み込みでいうとハードに近い場所(どうしても物理的なレジスタ、カウンタ等の数だけ分岐させる必要が出る場合など)に大きくなりがち7で、そういった処理を下手に分割すると逆に凝集度が下がったりするのが悩みどころですが、基本的なビジネスロジックでは推奨値を超えることはないでしょう。
循環的複雑度が守れていれば違反することは少ないので、この指標の優先度は下がるかもしれません。
呼び出しレベルの数 (Number of Call Levels)
入れ子(ネスト)の最大深度です。(名前からはイメージしにくい。。)
if, for, while, switch-caseなどが対象。言われる前に視覚的にわかるので解消しましょう。この指標の推奨値は4以下です。
呼び出し元関数の数 (Number of Calling Functions)
対象の関数が、他のいくつの関数からコールされているかを表す指標です。ただし、一つの関数から複数回呼ばれた場合でも+1と数えます。
例えば以下の関数getVal()の呼び出し元関数の数は2です。
int getVal(){ return (a) } int func1(){ // +1 tmp = getVal(); aaa = getVal(); } int func2(){ // +1 tmp2 = getVal(); }
この指標の推奨値は5以下です。
普通に考えると「共通化してるんだから他関数から多数呼ばれるのは当然では?」となるわけで、この指標の真の目的が見えてきません。残念ながら(欧州系の規格ではありがちだけど)規格策定の背景や目的を解説している情報が見つからなかったため想像するしかないですが、Mathworks社のメトリクス説明には「より自己完結なコードでは上限値を守るべきである(https://jp.mathworks.com/help/bugfinder/ref/numberofcallingfunctions.html?lang=en)」と書かれており、この指標をあらゆる箇所に一律に適用するのは構造が複雑化・冗長化して嬉しくなさそうです。
またこの指標は関数単体というより、アーキテクチャに関する最適化を促すものとしても機能しそうです。うまく分離・共通化されたライブラリを使用するのはよいとしても、適切に階層化できていないとデバイスを直で操作するUtilityがそこかしこでコールされるようなことになり、その種の問題を定量的に示すことができます。ただその場合高い確率で修正困難だとは思うけど。説明・分析用にないよりマシってことかな…
呼び出された関数の数 (Number of Called Functions)
対象関数内で何種類別関数をコールしているかを表す指標です。わかりやすい。
例えば以下の関数funcの呼び出された関数の数は2です。
int hoge(); int fuga(); int func(){ return (hoge() + fuga()*hoge()) }
この指標の推奨値は7以下です。
これも呼び出し元関数の数と同じく、ソフト構造に由来する指標と言えます。新規で作る際に「何でも屋」みたいな関数・クラス設計はしないと思いますが、変更時にどれだけ階層化させるかの目安にはなりそうです。
non-OSなシステムでのmain関数(スケジューリングを行う部分)とかだと当然コールする関数が増えるので、適応する場合はアーキテクチャ設計を行ったうえで逸脱可能な関数を指定するのが良い運用だと思います。
関数パラメータの数 (Number of Function Parameters)
関数がとる引数の数です。以下の関数funcの関数パラメータの数は3です。
int func(int a, int b, char c)
この指標の推奨値は5以下です。
当然引数が多すぎると関数は複雑化していますが、Cで組む場合はグローバル変数とかポインタ経由すれば作り方次第でいくらでも入力を増やせる8ので、あくまで参考程度の指標でしょう。そのような作りを防ぐためにアーキテクチャ・設計パターンで縛った方がより効果的なので、他の指標よりは優先度低めかと思われます。
gotoステートメントの数 (Number of Goto Statements)
gotoの数です。この指標の推奨値は0です。
特に言うことはない。…と、片付けても良いですが、returnステートメントの数と合わせてまあまあ議論を呼びそうな指標です。
むやみやたらにgotoを使うべきではないのは自明ですが、gotoを使うと嬉しい場面もないことはないです。ぱっと思いつくのは
- 多重ループからの離脱
- early return(に準ずる処理)
ですね。前者は抜けようと思うとフラグを設けるか、あるいは関数化してearly returnさせるという方法になるでしょうか。後者も同様に、「関数の冒頭で、その後の処理について関心があるかどうか」を判定し、無関係な処理はskipするという使われ方が想定されます。このような場合に、goto (または early return)を許容しないと逆に関数が複雑化するという主張もできそうです。
これに対する明確な答えはないですが、そもそもこのルールが制定されている背景が構造化プログラミングから来ているとすると致し方ない面もあります。その辺の考察については以下が参考になりますね。
結局のところ、明確なbetterがない中では「何を優先するか」は設計者によってまちまちであり、設計を統一しないことによる品質低下を防ぐために当時主流であった「構造化プログラミング」の文脈で一つのルールを作った、という解釈に落ち着きそうです。特にほとんどが実績重視の派生開発となる車載事業では、ソフトウェアとしての寿命が長くなる傾向にあり、開発に携わる人の延べ人数が他業界と比較しても多くなると考えられるため、設計を一定のルールで縛るのは致し方なかったと思われます9。
現代的プログラミングを学んできた方々、「こんなやつらと仕事したくない」と罵倒するのをこらえてどうか優しい目で見守ってください。。
命令の (Number of Instructions)
関数内に含まれる命令の数についての指標です。
;で終わる文を1命令とする(空の場合はカウントしない)- 変数宣言は、初期化されている場合のみ1命令とカウントする
if,for,while,switch-case,break,returnなどの制御文は1命令とカウントする- ただし、
caseラベル自体はカウントしない
- ただし、
例えば、以下の関数func()の命令の数は8です。
int func(){ int i, j=0, k=0; // +2 for(i=0; i<10; i++){ // +1 if(j==1){ // +1 k++; // +1 }else if(j==2){ // +1 k--; // +1 }else{ // 直前のelse-ifとセットのためカウントしない ; // 空のためカウントしない } } return (k); // +1 }
この指標の推奨値は50以下です。
単純に命令が多いと関数がそれだけ縦に長くなるので、おのずと関数化したくなる気がします。1行1命令として、コメント抜きでだいたいフルHD1画面に収まる長さって感じかと(エディタやフォントサイズにもよりますが)。まとまっと初期化処理とかでもない限り実現できそうですね。「子関数化の目安」をわかりやすく定量化したものと言えそうです。
returnステートメントの数 (Number of Return Statements)
returnの数です。推奨値は1以下です。
gotoステートメントの数で述べた通り。平和にいこう()
言語スコープ (Language Scope)
少し特殊な指標です。
とし、(N1 + N2)/(n1 + n2)の値を言語スコープと呼びます。
例えば、以下の関数funcでは
int func(char i){ if (i == 0){ return i; }else{ return i * func(i-1); } }
- 出現した演算子の種類
n1は13int,(,),char,{,},if,==,return,;,else,*,-
- 出現したオペランドの種類
n2は4func,i,0,1
- 全ての識別子、オペランドを数えると、
N1 + N2= 32
よって、言語スコープは(23 + 9) / (13 + 4)より約1.88 となります。この指標の推奨値は4以下です。
かなり計算がめんどくさいので、実用的な関数に対して人力で求めるのは無理でしょう。この指標は「保守または変更にかかるコスト」を測定するものらしく、例えば
といった具合です。同一演算/同一オペランドを多数使用するということはある種の冗長さが含まれている可能性もあるため、処理や構造改善の気付きになるかもしれません。まあ設計段階でこの指標を測定できないので結局作ってから改善するしかないのですが10。そういう意味では微妙に役立ちにくそう。
終わりに
車載部品開発でよく用いられるコーディングメトリクスについて一通り書いてみました。当然ですがあくまで下流工程での指標であり、それより優先すべき設計思想やアーキテクチャ設計などがあればこの限りではありません。
あんまり他業界とか担当外製品のことはわかりませんが、これ全部守れてる or 妥当な逸脱理由を持っているってとこは流石に稀かと思います。結局はソフトウェアは常に陳腐化・レガシー化のリスクにさらされており、改善し続けるしかないのかもしれません。
次、元気があればMISRAとかにも触れたい。元気があれば。(保険かけとく)
-
車載ソフトウェアの品質保証を標準化するために設立された、ドイツの自動車メーカ5社からなる組織。↩
-
HISメトリクスが策定された背景も同じ理由です↩
-
みんな大好き『リーダブルコード』にあるとおり↩
-
マイヤーズインターバル(Myer’s Interval)、アキヤマ指標など。↩
-
ここでいう制御フローはif, for等の制御文により発生する
{}ブロックを指します↩ -
筆者の経験上の最大値は5億越えでした。南無。↩
-
組み込み用途ではスタック消費を抑えるために静的変数へのアクセスを多用する場合もある↩
-
当然「基準を見直せばいいじゃないか」と言いたくなりますがそこは実績重視の(ry↩
-
そして「現状正しく動いているコードを変更できない」呪いによってレガシー化していく↩