macOS + vscode + clangでatcoder C++デバッグ環境構築
ソフトウェアエンジニアっぽくない仕事ばかりして久しいですが、最低限コーディングとかアルゴリズムとかわかっていたいと思う自分がいるのでatcoder始めてみました。昔すこしだけpythonでやってたんですが、コード解説とか多い&仕事とかで今後使うかも ということでC++でやることにする。
vscodeでC++デバッグ環境を作るのが初めてだったので備忘録として残しておく。
環境
- macOS Monterey 12.6.3
- VSCode 1.77.3
- Apple clang version 14.0.0 (clang-1400.0.29.202)
- lldb-1400.0.38.17
インストール
clangを使います。atcoderやる上では特にgccでもclangでも困ることはないですが、
- clangはstdc++.hがデフォで入っていないため、自分でファイルを置いてやる必要があります
- gcc + vscode + gdbでvscode上のデバッガ実行しようとしましたが、コンテナ内部の値が見れない現象が発生しました。(元記事はここhttps://github.com/Microsoft/vscode-cpptools/issues/69のようです) 色々試しましたが解消しなかったため、clang + lldbでやっています
clang
XCodeをインストールすれば勝手に入ります。lldbも入る。適当に調べて入れるだけ。
競プロ用途だと特に困らないと思いますが、XCodeで入るclangはAppleが手を加えた少し古いバージョンなので、最新機能などは使えないため注意が必要です。(最新版はHomebrewで入れられそう、詳細はここhttps://students-tech.blog/post/install-clang.htmlとか)
またmacだと自動でgcc→clangのシンボリックリンクが貼られるそうで、gcc使ってるつもりが実は裏でclangが動いてた、みたいなことになるため注意。gccを使いたければHomebrewでgccインストールする必要あり。
bits/stdc++.h
atcoderではよく使うライブラリ全部入りのbits/stdc++.hというヘッダファイルをインクルードすることが多いが、clangにはデフォルトで入っていないので自分で入れてやる必要がある。(この辺がめんどくさいからgcc使っている人も多い気がする)
以下ファイルをstdc++.hとして保存し、/usr/local/includeにbits/作って置くだけ。
Linux GCC 4.8.0 /bits/stdc++.h header definition with <cstdalign> error fixed. · GitHub
(GCC 4.8.0 bits/stdc++.h って書いてるからちょっと古いかも?とりあえず困らないのでこれでいく)
以下のサイトまんまなので困ったら↓を見る or 適宜ぐぐる
vscode
インストールは好きにやる。C/C++の拡張は入れておく。
tasks.json
ビルド設定をします。以下をtask.jsonとしてプロジェクトディレクトリの.vscode/配下に保存します。
{ "version": "2.0.0", "tasks": [ { "type": "cppbuild", "label": "C/C++: Build with Clang", "command": "/usr/bin/clang++", "args": [ "-std=c++17", "-stdlib=libc++", "-g", "-O0", "${file}", "-o", "${workspaceFolder}/a.out" ], "options": { "cwd": "${fileDirname}" }, "problemMatcher": [ "$gcc" ], "group": "build", } ] }
コンパイラ設定は以下公式にあるものを参考に設定している。
tasks.jsonを作成すればcommand + shift + bでビルドできるようになります。デバッグ時、最適化がかかっていると上手く動かないことがあるので-O0を設定しておく。task.jsonはビルドタスクだけでなく、順次実行するタスクであれば色々記述できるらしいので気になる方は調べてみてもいいかも。以下参考
launch.json
vscodeによるデバッグ実行時の設定などを、各言語に合わせて記述する。atcoder用設定は以下。
{ "version": "0.2.0", "configurations": [ { "name": "(lldb) Launch", "type": "lldb", "request": "launch", "program": "${workspaceFolder}/a.out", "cwd": "${workspaceFolder}", // "preLaunchTask": "C/C++: Build with GCC" } ] }
設定方法などは以下を参照。
大体デフォルトでよいが、いじるのは以下項目くらい。
- program: デバッグ対象の実行ファイル。vscodeで開いたディレクトリ直下に置く想定。
- preLaunchTask: デバッグ実行前に実行するビルドタスクを指定できる。
tasks.jsonで記述したlabelを指定する。 自分はビルドはcommand + shift + bでやることが多いので一旦コメントアウトしています
c_cpp_properties.json
C++のビルド設定など。
{ "configurations": [ { "name": "Mac", "includePath": [ "${workspaceFolder}/**" ], "defines": [], "macFrameworkPath": [ "/Library/Developer/CommandLineTools/SDKs/MacOSX.sdk/System/Library/Frameworks" ], "compilerPath": "/usr/bin/clang++", "cStandard": "c17", "cppStandard": "c++17", "intelliSenseMode": "clang-x64" } ], "version": 4 }
特筆すべきところはない、、と思う。compilerPathは忘れずにclang++にする。atcoderはc++17採用なのでcppStandardを適用しておく。
解いてく
会社が買収されたのを機にキャリアを考え直して転職した話

この度一念発起して転職したのでその記録。外的要因もまあまあ強いため参考にはならないかもしれませんが、今の時代「自分の会社が倒産しない」と言い切れる業界はほぼなく、あっさり買収されて環境激変することも容易にあり得ます1。そんな時できることは何か、あるいはそうならないように必死に働くか(一人で頑張ってもあんまり意味ないけど)、日頃から考えておくのが良いと思います。
以下略歴
- 地方国立理系院卒29歳♂(実務経験4年6ヶ月)
- 情報工学専攻(画像処理とか機械学習とかやってた)
- まあまあホワイト(高待遇)で有名な企業の車載部門に入社
- 伸び悩んではいたが利益率 4~5%ぐらいは出ており、グループ的には主力事業の一つだった
- 連日誌面を賑わせてるアレな会社(業績はすごい) に買収される
なんでやめたの?
M&Aにより事業方針が大きく変わった&待遇が目に見えて悪化していったので、出るなら早い方が良いと判断しました。
主な業務はモータ制御に関するECUのソフトウェア開発でしたが、実態としてはハードの下回り部分のみ受託して作っており、肝心の制御部分や通信・診断など付加価値の高いアプリケーションは客先担当というものでした。いわゆるTier2という立場ですね。まあ下回りでもプラットフォーム化して移植性高くしてやればソフト的な価値はあるんですが、ガチガチのハード依存&仕向けごとに別開発のためソフト共通化もノウハウ共有もうまくいってないことが多かったです。AUTOSAR準拠もできずに「とりあえず客先モジュールは実装できるような状態」にしてる、みたいな。結構そういう組織は多いんじゃないでしょうか。知らんけど。
そういった組織では基本的にハード主体で開発が進められることが多いと思います。角度補正や制御、各種信号のフィルタ設計など工学っぽくて面白そうな部分は客先 or 社内ハード担当が検討することになり、ソフト担当は基本的に言われたことをやる御用聞きに回っていることが多かったです(あるあるかもしれん)。
この時点で業務への満足度はかなり低かったのですが、一方で「流石に制御技術とか自社内で持ってないのはどうなのよ」って会社も思ってたようで、そこを強化する方針には概ね同意していました。ですが事業方針転換により足元の業績優先(親会社の注力分野への資金確保)のためにより受注額が大きい案件を取りに行くようになり、自社内の制御技術開発が無期限停止となって今に至ります。
そもそも入社時は、制御系よりはセンサーやIVI系など「情報処理が主機能」の製品の方が関心が高かったのですが、元々やっていたセンサー関連事業は金がかかるってことでこれも買収後ポシャりました。まあビジネスはシビアだししょうがないね。これが弱小車載メーカーの現実です。
待遇面では、まず基本給が下がりました。詳細は割愛しますが、結構騙し討ち的に下げられたためここで不満・不信感を持って去っていった人はまあまあいた印象です。あとは財形貯蓄など一部福利厚生も無期限停止されたり、交通費や年金(DCの会社拠出額)をジリジリ減らされたり。まあ赤字なら仕方がないんですが、度重なるコスト削減により、営業利益率10%は出るようになったのに目標過達を要求され待遇は悪化していくという不思議な感じになってました。偉い人曰く「10%以下は赤字、15%は達成せよ」とのこと2。なんも言えねえ。。。
ネガティブな理由ばかり並べましたが、ある意味強制的に環境を変えられたため本気で今後のことを考える良い機会にはなりましたね。
転職活動
現職の経験から「言われたものを言われた通りにきっちり作る(それ以外はしない)」みたいなのは性に合わないなと思い、かつ興味のある領域をざっくり考えてみたところ
- 組み込みソフトのスキルをある程度活かせる(must)
- OSやプラットフォームなどコアな部分をつくれる
- 付加価値の高いアプリケーションやサービスを上流からつくれる
みたいなのに落ち着きました。2番目と3番目は両立は難しいので、より上流側に行く/コアな部分を極める の2択と考えてました。ただ、やはり下回りをガッツリ作っているところは少ない印象です3。それ自体を自社製品として売り出しているところはさらに少ないので、自社ではなく受託を含めて検討してみました。
転職サービスはdodaとビズリーチを使っていました。doda(だけじゃないかもだけど)はエージェントの当たり外れがひどいと評判ですが、自分は当たりだったのか好みの求人を持ってきてもらえることが多かったです。ただメールは多いので覚悟したほうが良い4。最初は色々な会社を知るために目を通してましたが、途中からノールックでゴミ箱行きでした。あといきなり外人のスカウトから電話かかってくるのはびっくりするのでやめてほしい。
ビズリーチは企業から直接スカウトもらえるのは嬉しいですね。何度か企業の人事担当とお話ししましたが、なんとなく自分の相場観というものが測れる気がします。エージェントも評判良いらしいのですが、2社同時並行でやり取りできる自信がなかったのでやめました。もし次転職するときはビズリーチ使うかも。
そんなこんなでいろいろ探して7社ぐらい応募したところ
- 4社 書類落ち
- 1社 一次面接落ち?(合否前に辞退)
- 2社 内定
となりました。車載関係ないとこ(半導体系とか)も応募してみたんですが、意外と書類が通らないもんですね…まあその程度の経験しか積んでいないと言われればそれまでですが…
内定をいただけたとこについて軽く書きます。
大手メーカー研究開発部門の子会社
大手メーカーの研究開発部門の子会社として、ソフト開発を受託している会社です。自社ではハードを作らず、ソフト領域を上流〜下流まですべて手がけるという立ち位置でした。
人事担当が親会社の元研究職だったらしく、面接時にやたらソフトウェア開発に対する姿勢とか品質担保の考え方みたいなことを重点的に聞かれてちょっと焦りましたが、なんとか乗りきりました。この手の質問はプロセスとトレーサビリティと上流でのあくなき折衝を持ち出しておけば否定はされにくいと思います。それ以外の面接官は形式的だったのでそこまで印象に残っていない…
あとwebテスト(おそらくCABと呼ばれるもの)を受けました。法則、命令、暗号といった初見ではまあまあ難易度高いやつです。体感半分も解けずに絶望してましたが、なぜか通ったので中途採用においては参考程度にしか見ていないのかもしれません。webテストだめだめでも全然挽回できるよ!
最終的に内定を頂けましたが、より志望度の高いところに内定したため辞退しました。
大手SIer組み込み子会社
就活人気ランキング常連の大手SIer…の子会社です。グループ内での組み込みシステム開発の中核を担っており、プライム案件もそこそこある&ソフトの内製率が業界内でも高いのが強みだそうです。組み込み機器だけでなくクラウドやサーバ技術も自社で持っており、IoTサービス開発に力を入れている点に非常に魅力を覚えました。車部品の下請けの下請けやってた田舎っぺには眩しすぎる。
1次面接で焦りすぎてめちゃくちゃしどろもどろになり「絶対落ちたわ」と思っていましたが、逆質問で技術習得についての熱意をアピールしまくった結果なんか通りました(それが主因じゃないかもだけど)。意外とわからんもんだね。2次面接は特に問題なく終わったのでほぼ記憶にないです。webテスト(たぶん玉手箱)は言語と計数でしたが、だいたい7割ちょいは解けた気がするので心配はなかったですね。
無事内定をいただき、承諾しました。
これから
新天地で、まずはコックピット系の車載部品開発に携わりそうです。今まではNonOSなシステムしか触ったことないのに組み込みLinuxとかやることになりそうで戦々恐々としていますが、やっていきの精神で頑張ります。
その後はその時やりたいことに飛びついていく感じでいこうかなと思います。自分が飽きっぽいというのもありますが、一つの分野を突き詰めて価値を出すというのが存外難しいことなのだと社会人になって常々感じていたので。前職ではそれなりに貴重なハード周りのソフト開発経験を積めたので、これからは組み込みに軸足を置きつつクラウドとかWebとかやるのかもしれません。あいおーてぃー人材目指す。
真に成果を上げる組織に必要な『心理的安全性のつくりかた』
「心理的安全性」というワードがここ最近で急に浸透してきているように感じたので、教養としても知っておきたいと思い呼んでみました。マネジメント向けとされていますが、サブリーダーやメンバーといったレベルでも実践できることが多く、役立つことが多いです。

著者
株式会社ZENTech取締役、チーフサイエンティストの石井遼介氏が執筆されています。略歴はここ。『組織・チーム・個人のパフォーマンスを研究し、(中略)心理的安全性の計測尺度・組織診断サーベイを開発するとともに、ビジネス領域、スポーツ領域で成果の出るチーム構築を推進』しているそうです。なんかすごそう。
本書の中でも言及されてますが公演もよくやっているそうです。
概要
- (日本における)心理的安全とは、以下が保証された状況をいう
- 率直な意見や問題などの「話しやすさ」
- トラブル対応や成果物品質向上のための「助け合い」
- 時代の変化・状況の打開のための新しいことへの「挑戦」
- 多様な観点から変化に対して対応する「新奇歓迎」
- 組織のカルチャーを変えるためには心理的柔軟性を持つ
- 「変えられること」と「変えられないこと」を見分ける
- 「変えられないこと」は受け入れる
- 「変えられること」に取り組むために、「大切なこと」を明確化する
- 組織改善の施策その1 動物行動に基づく『行動分析』
- 組織改善の施策その2 言語行動に基づく『ルール支配』
- 人間は言語を扱うことで、好子・嫌子を超えた長期的みかえりを意識した行動ができる(ルール支配行動)
- ルール支配行動は3段階ある
- 言われた通り行動:行動そのものからではなく、ルールを提示した人からのみかえりによるもの。ルールに疑問を持たず、現状脱却できない
- 確かにそうやな行動:行動から得られるみかえりによるもの。ルールに誤りがあっても訂正可能である
- そんな気してきた行動:行動から得られるみかえりを増強/減少させるもの。ルール(きっかけ)自体が行動の強化・弱化につながる
- みかえりとルールをセットで説明し、確かにそうやな行動を増やす
- 組織/個人にとって大切なことを言語化し、そんな気してきた行動を増やす
実践
行動レベル(より小さい範囲)と関係性・カルチャーレベル(より大きい範囲)で、心理的安全性導入に関するアイディア集が紹介されています。それぞれすぐできそうなことをあげてみます。
感謝から始める
精神論ではなく、「他人がとった良い行動を強化するための好子」として感謝を伝えることには意義があります。特に漠然と「ありがとう」ではなく、
- いつ、どんな状況で
- どんな行動が自分にとってありがたかったか
と掘り下げることが大切だそうです。人によっては「そんな大したことしてないし…」と卑下とも取れる謙遜をされることもありますが、主語をあくまで「自分」とすることで、「あなたがどう思っていようが私は助かった」と伝えるとより好子としての働きが強まると考えられます。
さらに感謝を効果的に伝えるには、その人のことを普段から気にかけている・よく見ていることを明示するとよいと書かれています。全然気にかけてくれてない人から急に感謝されても、薄っぺらでとってつけた言葉と思われかねません。あくまで監視・マイクロマネジメントではなく、普段からの小さなコミュニケーションが重要ということですね。(一生言われてる)
のび太力を上げる
一人で解決できないことは他人を頼りましょう(本書では「のび太力」と呼んでいます)。特にリーダー的役割を担う人はこれを意識して行うことで、会話が促進されメンバー内の心理的安全を高めることができます。以下のような施策が効果的だそうです。
頼る:メンバーの役割や強みを把握し、頼る
自己開示:自分がどういう失敗をし、そこからどう学んだかを開示する
- 相手より一枚薄く鎧を着る:立場やプライドの自己防衛に徹するのではなく、相手より少しオープンでいる
どれも自分が苦手としているところなので積極的に実践したいですね。。
心理的安全であることを宣言する
こちらは組織レベルでの案ですが、心理的安全を宣言し、メンバー全員の意識を振り向けることが大切だと述べられています。特に立場が上の人がやる必要がありますが、例えば会議冒頭で「あらゆる意見・アイディアを歓迎する」「失敗や問題の報告は絶対に叱責せず、解決策を検討する場とする」といった宣言をするだけでも雰囲気は変わるでしょう。これを継続することでメンバー内にも心理的安全の意識が芽生え、互いの存在が「心理的非安全な行動を弱化させる」嫌子として働くと予想されます。
おわりに
現代的なマネジメントの基本である心理的安全について学びました。たとえマネジメントはしなくても、会社で働いている以上新人教育は必ず必要になるので、いつ自分が「上に立つ」立場になってもいいように、心理的安全性について知っておくことが大切だと思いました。圧の強い上長とかNoと言わせないリーダーに読んでほしい
VSCodeに慣れ切った人間が限界までサクラエディタを使ってみた話
サクラエディタ、使っていますか?
自分は新卒入社時、先輩に謎マウント1取られて以来忌み嫌っていたのですが、何事も経験せず批判するのも良くないなと思い、とりあえず限界までカスタムしたらどれくらい使い物になるのかを試してみました。ちなみに普段はVSCode使いです。
結論から言うと
みたいな使い分けに落ち着いています。
コードリーディングにはそこそこ不自由なく使えるようになりますが、やはりがっつりコーディングするのはきついです。また筆者がよく使うのはC、アセンブリ、python、VBA(VBScript)くらいですが、せいぜいCかアセンブリくらいにしか使いません。というかVSCodeが便利すぎるので、特別な理由がない限りVSCodeに落ち着きますね。。
静的解析ソフトとかクソデカ神エクセル仕様書とかを立ち上げながらコード読みたい時がちょくちょくありますが、そう言うときはサクラエディタの方が軽いのでよく使います(PCのスペックにもよる)。
VSCodeとの比較と、実際に行ったサクラエディタの設定などを書いていきます。記事執筆時点で以下verを使用しています。
- SakuraEditor == 2.4.1
- python == 3.8.10
設定ファイル、マクロ等はここに置いてます↓
比較
しばらくサクラエディタを使ってみて感じた、VSCodeと比較していいところ・イマイチなところを挙げてみました。
いいところ
軽い
最大の長所。サクラエディタに限らず、軽量エディタを使う理由の9割以上はこれだと思う。試しに60000行越えヘッダファイルをサクラエディタとVSCodeで開いてみると、圧倒的にサクラエディタの方がメモリ消費、CPU負荷が少ないことがわかります(開くファイルとかVSCodeに入れてる拡張機能にもよるけど)。編集時もVSCodeは若干もっさりしますがサクラエディタはサクサクです。
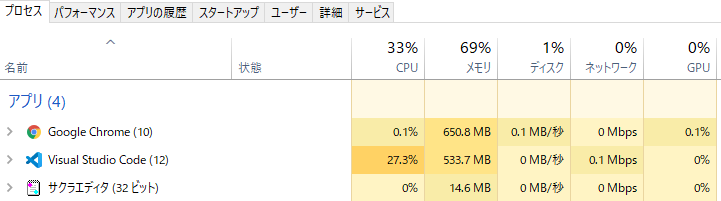
まあここまで巨大なファイルを編集することは稀なので、サクラエディタに有利な問題設定なのは否めないけど…普通に使う分には、「動作の軽快さ」でいえばVSCodeの方が上です。VSCodeは起動時にファイルやフォルダの内容を読み込むことで、軽快な動作を実現しています。サクラエディタはgrepやタブ切り替え時に逐次処理を行うため、動作としては若干ラグがあります。
外部マクロ実行
外部ファイルを読み込んで操作の自動化等ができます。形式は
- WSHマクロ(
.vbsor.js) - キーマクロ(
.mac) - PPAマクロ(
.ppa)
が利用できるとのこと。
主に使うのはWSHになるでしょうか。WSHからはマクロ専用関数が利用でき、これを使うとサクラエディタに実装されていない機能でも擬似的に機能拡張することができます(実際欲しい機能がないので作りました、後述)。これなかったらわざわざサクラエディタ使わんと言っても過言ではない。
キーマクロは一連のキー操作をマクロとして記録し、自動実行できる機能です。キー操作とは言っていますが、サクラエディタは全てのコマンドをショートカットキーに割り当て可能らしいので、事実上あらゆる操作をキーマクロで実行できます。ただExcelならまだしも、プレーンテキストに対して特定の操作を繰り返し実行したいと思ったことがないのであまり使いませんが…
PPAはPoor-Pascal for Applicationというものらしく、Pascalで記述したマクロ機能を実装するためのフリーウェアだそうです。わざわざPascal使うことない(しかもPoor-Pascalってことで言語機能も限られる)し、DLLのダウンロードが必要なのであえて使う意味はないでしょう。結局のところWSH頼みですね。
謎の信頼を得ている
会社/組織によっては使うソフトなどが厳密に定められているところもありますが、サクラエディタが禁止されているというところは聞いたことがありません。おそらく「外部との通信をする機能がない」とかそういうところに起因するものと思われます。普段使いのエディタを禁止されると著しく生産性が下がりますが、サクラエディタを使えるようにしておけばとりあえず安心はできるでしょう2。
イマイチなところ
シンタックスハイライトが弱い
コードエディタとして利用する上での最初の壁です。デフォルトでは予約語、リテラル、コメント しか色分けしてくれません(辞書を編集することはできるけど結局予約語と同じ扱い)。これはプレーンなエディタの限界でもありますが、VSCodeだと自動でフォルダ内すべてのファイルに対して構文解析が走るのに対し、サクラエディタは現在開いている1ファイルしか見ることができず、特に構文解析もしないためシンタックスハイライトが難しいものと思われます。
自分的には最低でも、関数・定数までは視覚的に色分けされてて欲しかったので、少しでもマシになるように設定を作りました。カラー設定参照。
入力補完が微妙
これも致し方ないですが、デフォルトだと辞書 or 編集中のファイル くらいしか補完候補の単語を拾ってくれません。一応ctagsの出力ファイルを利用するプラグイン拡張でそれっぽく動かすこともできますが、tagsファイルが大きいと補完候補の表示処理が激重でサクラエディタの長所が消滅します。コーディングするときは大人しくVSCode使った方が良さそう。
ファイルに関する操作
エディタ上でファイルツリーを表示する機能はありますが、視認性・操作性は現代的エディタと比べると劣ります。それだけならまだ良いですが、サクラエディタには「ファイル名で指定して開く」といった機能がありません(goto Anythingとか言われる機能、VSCodeならCtrl + E or Cmd + P)。開いているファイルの場所をエクスプローラで開く、みたいな代替っぽい機能はありますが「違う、そうじゃない」と言わざるを得ない。
コードを読む上では必須級の機能だと個人的には思っているので、外部マクロで簡易的なものを作りました。後述。
Windows専用
どれだけ設定を作り込んでも他OSでは使えません。しゃーない。
どちらともいえないところ
プラグイン拡張
ないよりはあった方がいいけど、まだ微妙に使いこなせていません。プラグイン拡張では、
- アウトライン解析の外部実装
- スマートインデントの外部実装
- 入力補完の外部実装
- メニューコマンドの追加
を実現できます。一番欲しかったのがプロジェクト内シンボルの入力補完ですが、先に述べたように動作がイマイチなのであまり使っていません。なんかいい方法あるのかな。
設定したこと
ここからは、実際にサクラエディタを使う上での設定や作成したマクロなどを紹介します。
フォント
デフォルトのMSゴシックは視認性が悪いので変更します。個人的おすすめはHackGen。
サクラエディタは英文・和文で別々のフォントを設定することができないため、必然的に両対応の等幅フォントが候補になります。「等幅フォント プログラミング」とかでググれば色々出てくるのでこだわると楽しいかも。
ショートカット
デフォルトのショートカットをVSCodeっぽくします。よく使うのは↓
| 操作 | コマンド |
|---|---|
| grep検索 | Ctrl + Shift + F |
| 置換 | Ctrl + H |
| grep置換 | Ctrl + Shift + H |
| 行指定でジャンプ | Ctrl + G |
| タグジャンプ | F12, Alt + ダブルクリック |
| ダイレクトタグジャンプ(シンボル指定ジャンプ) | Ctrl + T |
| カーソル位置の単語を選択 | Ctrl + D |
| 行末まで削除 | Ctrl + Shift + K |
| アウトライン表示(トグル) | Ctrl + B |
| 対括弧の検索 | Ctrl + Shift + \ |
また、サクラエディタ特有の機能を以下に割り付けています。
| 操作 | コマンド |
|---|---|
| 右タブをすべて閉じる | Ctrl + Shift + W |
| tagsファイル作成 | Ctrl + Shift + A |
| 検索マークの切替え | Ctrl + Q |
タブ表示設定で使用すると、grep結果が毎回新規タブで開かれるためどんどんタブが煩雑になります。それらを一括で閉じるためのコマンドをショートカットに割り当てました。またコードリーディングに必須のtagsファイル作成もコマンド登録しています(マクロも作成しましたが後述)。Ctagsがデフォで入ってるのはありがたいですね。
VSCodeだと選択した単語に自動でハイライトっぽい表示をしてくれてすごく助かるのですが、サクラエディタは明示的にしてやる必要があります。そのためのコマンドが検査マークの切替え(Ctrl + Q)です。部分一致でもハイライトされて少し使い勝手が悪いですが、そのときは正規表現で検索するしかないですね。。
ファイル内検索時、次/前のヒット箇所に移動する際のコマンドがF3 / Shift + F3という微妙に押しにくい設定なので、これは変えてもいいかもしれません(自分は慣れてしまったので特に変えていません)。
個人的に欲しいと思った以下の操作が用意されていない or 使い勝手が悪いので、これらはマクロで作ります。
- カーソル行の下に行を挿入
- Tab/逆Tabインデント
- ファイルを指定して開く
カラー設定
基本
デフォルトのクリーム色も悪くないのですが、ダーク系に慣れているので調整します。また、シンタックスハイライトが弱い部分を追加の正規表現設定で補います。
ダークテーマについてはMonokai風設定を公開してくださっている方がいるので、そのまま使わせてもらいました。
選択範囲の背景色や文字色など、微妙に見づらく感じた個所は適宜変更しました。
正規表現
関数・定数のハイライトを正規表現で登録します。特定の正規表現にマッチするパターンを任意の色で表示できるのですが、完璧に色付けできるわけではないため多少は妥協し、「シンボル名から種別が判断できるもの」はハイライトすることにします。以下、C/C++用設定で作成した例です。
- 制御文の予約語:
/(if|for|while|switch|return|sizeof|case)[ \t]*(?=\()/k - 定数(すべて大文字の単語を定数と扱う):
/\b[A-Z_]+[0-9A-Z_]*\b[ \t]*/k - 関数名:
/[a-zA-Z_]+[0-9a-zA-Z_]*[ \t]*(?=\()/k
それぞれのパターンにマッチする箇所に対して任意の色でハイライト設定ができます。重複する場合は番号が若いものが優先されるようになっています。
まず関数名にマッチさせるパターン(3)を書きますが、関数呼び出し演算子()は制御文にも多用されるため、制御文のパターン(1)を定義しています。また今回の場合、「大文字+アンダースコアからなるシンボルは定数である」と決め打ちして、定数パターン(2)を関数より優先させています。
欲を言えば型名もハイライトさせたいのですが、シンボル名のみから型名かどうかを判断することができないため諦めます(コード規約とかで縛ればできんこともないけど)。まあ読めなくはないのでこれでよいかな。
マクロ
サクラエディタに外部マクロを登録することで、ショートカットから実行できるようになります。マクロはそれぞれリポジトリの以下ファイルと対応しています。
- カーソル下に行挿入:
InsertLine.mac - Tab/逆Tabインデント:
IndentTab.vbs,UnindentTab.vbs - ファイルを指定して開く:
open_file.vbs - プロジェクトを開く:
open_project.vbs - tagsファイル作成:
make_tags.vbs
後述しますが、下三つはpythonスクリプトとjson設定ファイルを組み合わせて実現しています。ざっくりと書くと以下のような構造です。
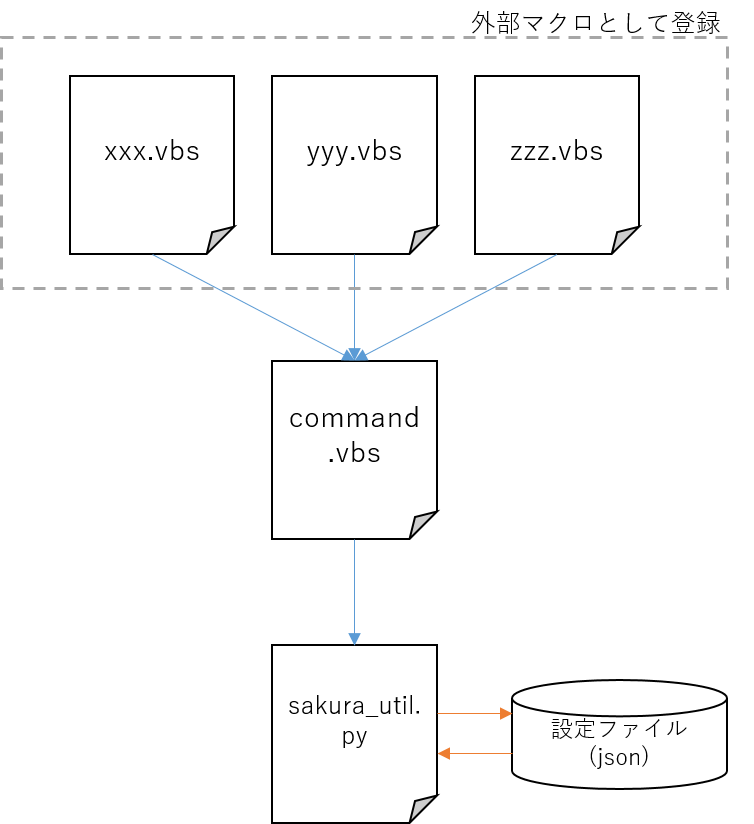
- サクラエディタへの登録用マクロ(
*.vbs) - pythonスクリプトと登録用マクロのI/F(
command.vbs) - 設定ファイルを読み込んで処理する用のpythonスクリプト(
sakura_util.py) - 設定ファイル(
macro_config.json)
といった感じです。登録用マクロひとつに1ショートカット割り当てるようなイメージなので、基本的には用途ごとにマクロファイルを作る必要がありますが、各々に設定情報を持たせると煩雑になるので設定ファイルにまとめました。設定ファイルは読み書きしやすいようjsonにしています。あと、pythonスクリプト実行時のコマンドライン入力を共通化したかったのでcommand.vbsを挟んでます。
それぞれのマクロ処理の詳細は以下参照。
カーソル下に行挿入
VSCodeでいうところのCtrl + Enterのやつ。地味に便利なのでキーマクロでつくります。
- 行末にカーソル移動
- 改行
をマクロ化し、Ctrl + Enterに割り当てるとそれっぽく動きます。
Tab/逆Tabインデント
Tab/逆Tabインデントは機能としては存在しますが、デフォルトだと
- 行選択しないとTabインデントが効かない
- 非選択時はTab/逆Tabインデントを受け付けない
という動作になります(仕様らしい)。微妙に使い勝手が悪いのでこれらのコマンドをWrapするマクロを作ります。
Tab/逆Tabインデントと選択範囲行の取得がWSHマクロから行えるので、これを利用します。TabインデントをCtrl + ], 逆TabインデントをCtrl + [に割り付ければVSCodeと同じ感じで使えますね。
ファイルを指定して開く
「ファイル名を入力し、プロジェクトフォルダ内のヒットしたファイルを開く」という動作を実現します。ここはある程度割り切って、以下のような動作をさせることとします。
マクロ実行時、ユーザから開きたいファイル名の入力を受け付ける
プロジェクトフォルダ内(あらかじめ登録しておく)のファイルを再帰探索する
最初にヒットしたファイルを開く(複数ヒットした場合を考慮しない)
探索対象であるプロジェクトフォルダのパスは何らかの方法で与えてやる必要があります。ファイル名入力と同時にユーザ指定しても良いですが、「ファイル名を指定して開く」という本来の目的を果たすために余計な操作が入るのが嫌だったので、あらかじめ設定ファイル等の形でプロジェクトフォルダのパスを指定しておくことにしました。現在開いているファイルがどのプロジェクトのものかを判断し、プロジェクトフォルダを探索対象として所望のファイルを開きます。
複数ヒットの場合のケアは迷いましたが、これを解決しようとすると対話的なインターフェースが必要になり、複雑さがかなり増すため諦めました。同名ファイルがプロジェクト内にある場合は大人しくエクスプローラから開くことにします。
マクロ登録部分のスクリプトはVBSで実装し、設定ファイル読み込み&ファイル探索などの処理はpythonで書きます。最初はVBSで書いてたんですが
- 再利用しにくすぎる
- 設定ファイル読み込みが面倒
- スコープ管理がむずい
という理由からpythonに頼ることにしました。VBSからはWSHシェルでpythonスクリプトを実行するひと手間が発生しますが、VBSで全記述するよりはやりやすいと思ったので許容します。設定ファイルはライブラリが使えそうなjson形式にします。
試しにサクラエディタのリポジトリをクローンし、ファイル名を指定して開いてみました。Ctrl + Eに割り付けるとそれっぽく動きます↓
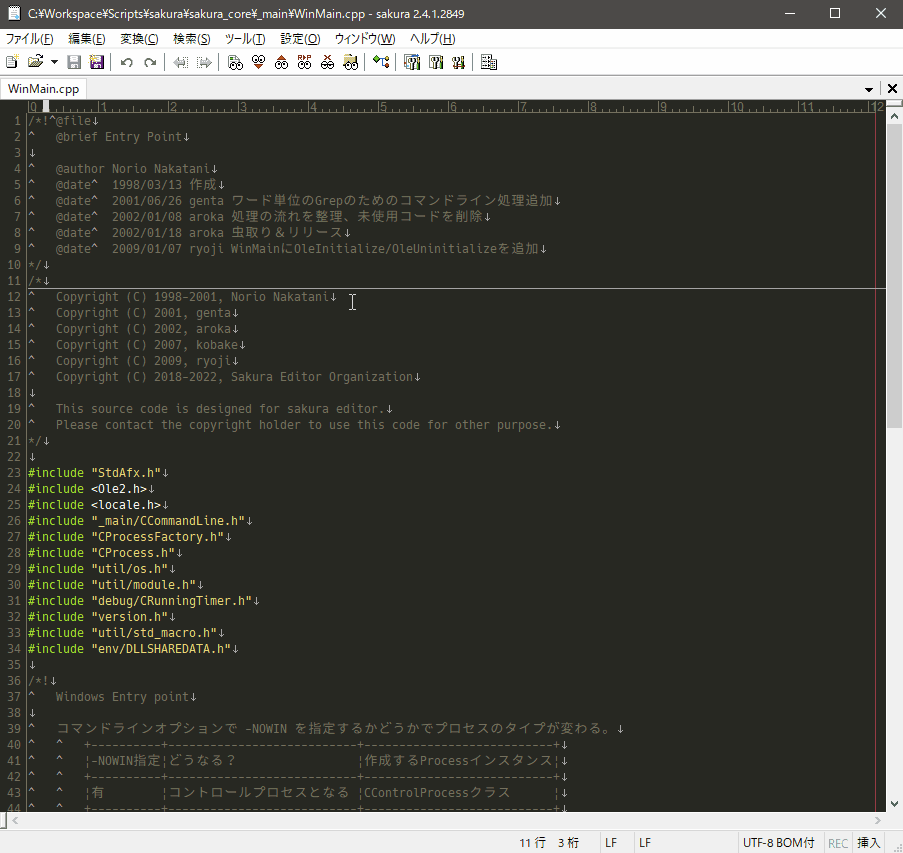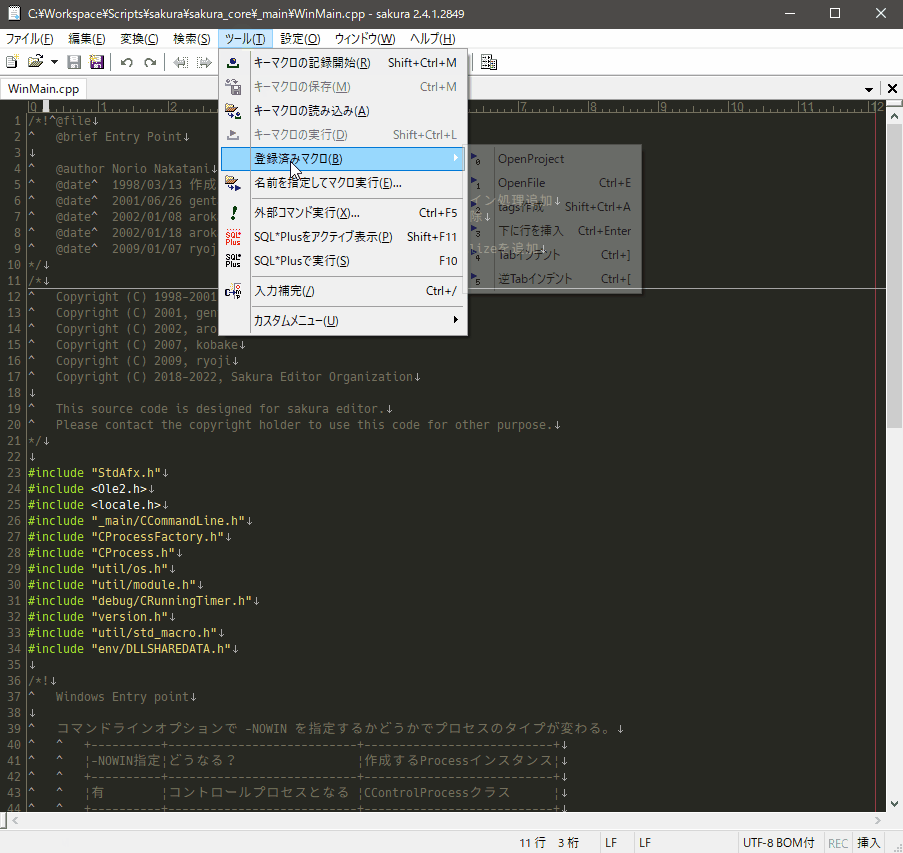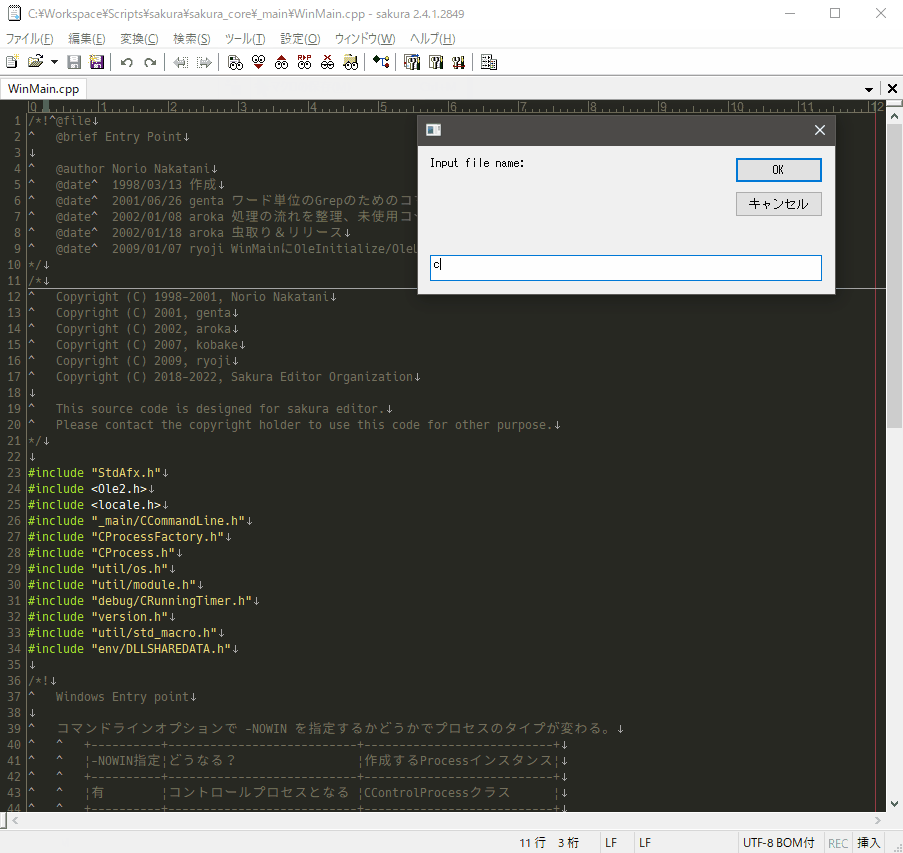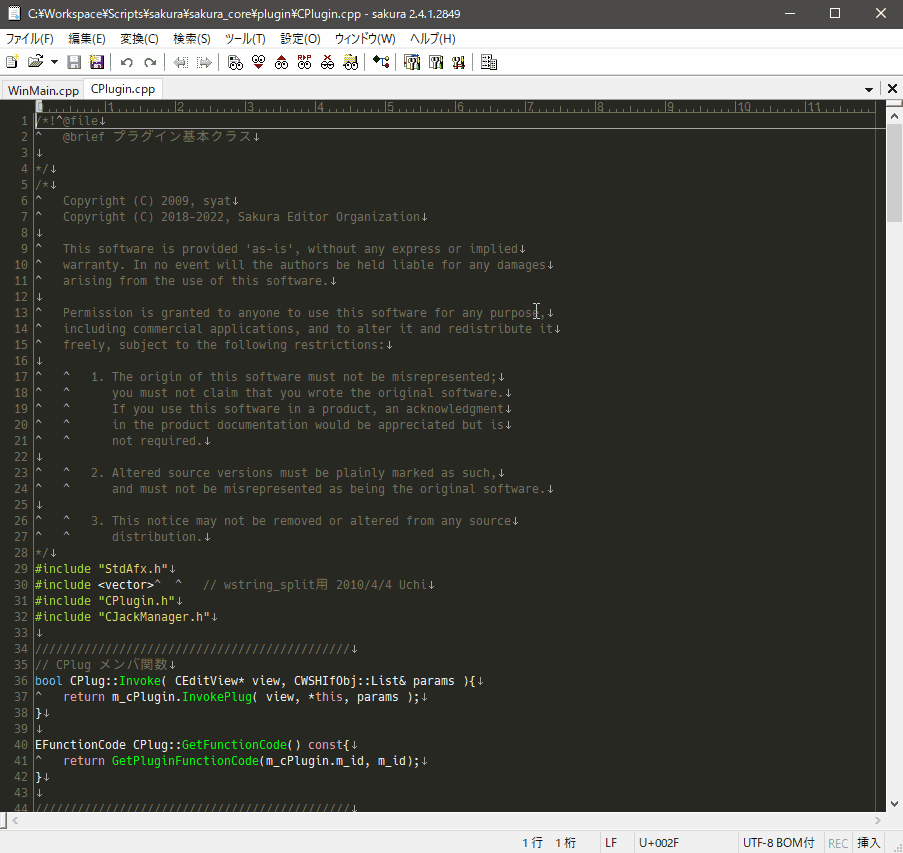
WshShell.Exec()を使用しているので一瞬コマンドプロンプトが表示されて少し気になりますが、特段困ることもなくやりたいことは実現できているのでよしとします。(頑張れば表示を無くすこともできるらしいですがめんどくさかった)
プロジェクトを開く
「ファイル名を指定して開く」のためにプロジェクトパスの情報を持たせているので、そこに「デフォルトのファイル」の情報もセットにしておけば「プロジェクトを指定して開く」ことも可能になります。ということでついでに作りました。
マクロ実行時、登録済みプロジェクトの一覧を表示し、ユーザからプロジェクト名の入力を受け付ける
指定されたプロジェクトフォルダに対し、「デフォルトのファイル」を再帰探索する
という手順を踏みます。先に登録済みプロジェクトを表示して入力を促すので、ちょっと対話的っぽい感じになりました。やってることは実質「あらかじめ登録しておいたファイルを開く」というだけなのですが、設定ファイルをコンパクトにしつつ使い勝手も悪くないのでまあまあ満足。
先ほどと同様、試しにサクラエディタのリポジトリをプロジェクト登録して適当なファイルを開いてみた↓

サクラエディタ起動→プロジェクトを開く とすればわざわざエクスプローラから指定して開く必要がなくなります。
tagsファイル作成
ctagsは指定した言語のソースファイルを解析してくれますが、当然指定した言語で想定しない文字列が含まれているとうまく解析できません。インラインアセンブリ(#pragma asmとかそういうやつ)を含んだCソースとかだと、そのファイルだけ解析されずシンボルジャンプできない、という事象が発生したためやっつけで作りました。tagsファイル作成機能をwrapするようなマクロなので、tagsファイルが普通に作成できるなら不要です。
以下の手順で処理を行います。
tagsファイルにはシンボル名と行数が記録されるため、tagsファイル作成時のみ無効な文字列(今回の場合でいうとアセンブリ記述)をコメントアウトすることで、期待通りのシンボルジャンプが実現できるようになります。
プラグイン
ctags入力補完だけ試してみました。結果、動作もっさりだったのでほぼ使っていません。
サクラエディタのwiki3にCtags入力補完プラグインが上がってたので使用しました↓
Plugin/投稿/10 - SakuraEditorWiki
一部文字コード比較のロジックがバグってたので、修正したものをリポジトリにあげています。
規模の大きいtagsファイルで使用してみるとわかりますが、入力補完トリガ後、1文字入力するたびにラグが発生します。おそらく文字入力毎にtagsファイル全体を走査し、候補リストを更新しているためだと思われます。これを解決するためには
- 入力補完トリガ時に一度tagsファイルを読み込み、候補リストを保持
- 文字入力毎に候補リスト内のみをチェックし、候補リストを更新
のような手順が必要な気がしますが、プラグインのみでは実現できないっぽいです。サクラエディタ開発の今後に期待(自分ではやらない)。
終わりに
ここまでやっておいて「結局VSCodeでよくね…?」となったのは言うまでもない。まだ改善の余地がありそうですが、やってる途中で我に帰ったのでキリのいいところでやめました。
誰得記事ですが一応そこそこ時間をかけたのでここで供養しておきます。
参考
ソフトウェア品質向上のために 〜HISコードメトリクス〜
結構前に、以下のようなツイートをしました
「if-else ifに対しては条件抜けがないことを明示するために書く」ってのがIPAが出してる組み込みソフトコーディングガイドに記載されてるので、それに準拠してるとこは書くかも https://t.co/Vdb7QZJXGt
— じっく (@zickuuu) 2022年1月8日
引用元ツイートはそこそこリプや引用もされてて、地味に(自分の中で)話題になっていたのですが、おそらく携わる業界によってかなり文化が異なるんだなあと改めて実感した事例です。
ツイートはMISRA-C 2012というC言語用のコーディングガイドラインが発端のものですが、組み込み系(特に高い品質が求められる製品)ではこれに限らず、さまざまな規約・ルール・要求等があります。ソフトウェア工学や統計的な観点から生まれたもの、エキスパート数名や何らかの組織から発足したものまで様々ですが、中には古い慣習から続けられているものもあります。
ここではそれらについて考え直す意図も含めて、車載ソフト開発の現場でソフトウェア品質向上のためにどのような方策がとられているか・その背景的なところを振り返ってみます。他業界よりも高信頼性が求められる傾向にある車載業界で実際に適用されている方法論はどんなものがあるか、といったことが知りたい人への参考になればよいかなと。
「そもそも品質とは何か」みたいな話はwikiなどを見るとわかりやすいかもです。
なお品質向上には開発プロセスのような抽象的アプローチから、「設計上のアンチパターンを回避する」といった具象・実装よりなアプローチなど様々な手段がとられますが、実装に近いほどイメージが沸きやすいため、そこから始めてみます。というわけでコードメトリクスについて考えていく。
- コードメトリクスとは?
- 主な指標
- プロジェクトスコープ
- ファイルスコープ
- 関数スコープ
- 循環的複雑度/経路複雑度 (Cyclomatic Complexity)
- パスの数 (Number of Paths)
- 呼び出しレベルの数 (Number of Call Levels)
- 呼び出し元関数の数 (Number of Calling Functions)
- 呼び出された関数の数 (Number of Called Functions)
- 関数パラメータの数 (Number of Function Parameters)
- gotoステートメントの数 (Number of Goto Statements)
- 命令の (Number of Instructions)
- returnステートメントの数 (Number of Return Statements)
- 言語スコープ (Language Scope)
- 終わりに
コードメトリクスとは?
品質担保の代表格、おおよそどの言語・プロジェクトにも適用しうる指標です。設計や実装の「良さ」を定量化したものとも言えます。レビュー観点として策定してしまえば、ある種機械的に合否を判断できる分、導入のハードルは低いです。
コードメトリクスは主に静的解析ツールで算出することができます(IDEで算出できるものもある)。ここではコードメトリクスの中でも、Hersteller Initiative Software(HIS)1で推奨されているメトリクスについて触れます。
主な指標
HISコードメトリクスはその対象範囲に合わせて、大きく3つのスコープに分類できます。
- プロジェクトスコープ
- ファイルスコープ
- 関数スコープ
プロジェクトスコープ
直接再帰の数 (Number of Direct Recursions)
いわゆる自己再帰関数の数です。この指標の推奨値は0です。
自分はECU開発ぐらいしか製品ソフトの開発経験がないので「どうしても再帰じゃないと困る」場面があまり思いつきませんが、仮に使用する場合は厳密に制御された上で使用する必要があります。再帰関数の使用で発生しそうな問題は
- スタックを大量消費する
- 複雑で動作イメージがわきにくい(保守コスト大)
- 使い所を見極めないと単純な
forよりも効率が著しく悪くなる - テストが困難
くらいでしょうか。特に車載部品が複雑化する昨今ではソフトウェアのサプライチェーンが長くなり、様々な知識・経験レベルの人間が関わることを想定2して開発しなければならないため、上記リスクを許容してまで再帰関数を採用する動機はほぼないでしょう。(あったらこっそり教えてください)
再帰の数 (Number of Recursions)
再帰には上記の直接再帰の他に、「間接再帰」と言うものもあります。二つの関数が互いにコールしあっているような場合ですね。この指標では、関数を頂点、コール関係を辺とした有向グラフを描いたとき、全ての頂点から他の任意の頂点に移動できるパスが存在するような頂点の集合を「強連結要素」と定義し、
- 直接再帰の数
- 強連結要素の数
の合計を計測します。
例えば以下のfunc1, func2, func3は、どの関数を始点としても任意の関数に到達できるため、強連結要素とみなされます。
int func1(){ if (a){ func2(); }else{ func3(); } } int func2(){ func1(); } int func3(){ if (b){ func1(); } }
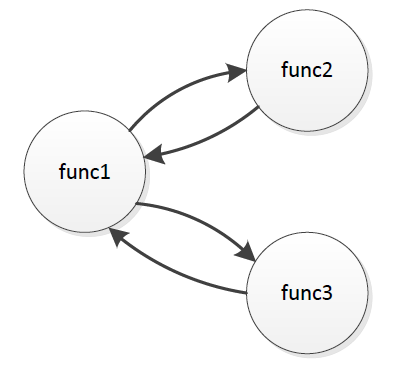
強連結要素はいくつの関数で構成されていても1と数えます。この指標の推奨値は0です。
そもそも普通に作ってたらそうはならんやろ…と言いたくなりますが、なにか特別なケースだとこういう設計の方が嬉しいことがあるんでしょうか。よくわからん。
ファイルスコープ
コメント密度 (Comment Density)
文字通りコメントの密度です。対象となるファイル内のステートメントとコメントの数の比率を計測します。以下の基準に従って、ステートメントとコメントの数を計算します。
コメント数 / ステートメント数 * 100 でコメント密度を算出します。この指標の推奨値は20以上です。(コード例を出して手計算するのがまあまあめんどくさいので割愛)
推奨値を達成するためにはおおよそ5ステートメントに1コメント書く必要があるわけですが、この量が多いか少ないかは賛否が分かれそうですね。コメントには冗長な情報を書くべきではないため3、ただこの推奨値を満足させるためにコメントを書くと可読性には逆効果となるためです。その辺のリテラシーが開発者には求められるでしょう。
この指標のミソは「複数行連続するコメントは1つとして数える」、「ソースで始まる行のコメントは無視」というところにあると思います。つまり
- できるだけ細かい単位でコメントを書くように促している
- 一行のみを修飾するようなコメントはカウントしない
というふうにメトリクスが作られています。「aにbを代入する」みたいな無意味なコメントを省きつつ、処理単位での設計意図や背景を書かせるようにしているものと予想されます。ソースコードではなくコメントに対して、実用に耐えうる指標を設けているのはなかなか興味深いと個人的には思いました。ただやはり指標だけハックしようと思えばいくらでもコメント量産されてしまうので、ある程度リテラシーは求められるかも…。頑張って意味のあるコメント書こうね。
関数スコープ
循環的複雑度/経路複雑度 (Cyclomatic Complexity)
関数内の判定点の数によって計算されます。ここでいう判定点とは制御フローが2つに分岐する点のことであり、
iffor,while(条件式が評価されない場合もカウント)switch-caseの、breakを含むcase- 三項演算子
?:
を判定点と呼びます。(ただし、&& , ||によるbooleanの結合は判定点として数えない)
判定点数の和に+1したものがその関数の循環的複雑度です。判定点が0の関数の循環的複雑度は1となります。
例えば、以下の関数func()の循環的複雑度は6です。
int func(){ if(A){ // +1 d = (a ? b : c); // +1 }else if(B || C){ // +1 // 処理 }else{ while(D){ // +1 swhitch(E){ case 1: case 2: // 処理 break; // +1 default: // 処理 } } } }
循環的複雑度は10以下が推奨となっています。
言われなくてもなんとなくわかりそうですが、判定点が多いとそれだけ可読性が悪化し、テストケース設計が困難になります。また「その関数内で多様な判断をしている」と考えると、凝集度が低くなっている可能性があります。比較的計測しやすく、設計見直しの指標としてもそれなりに効果的なので気にして損はないと言えそうです。
経路複雑度とも呼ばれ、これを拡張した指標4もあります。
パスの数 (Number of Paths)
その関数内で実行しうる静的経路数です。path coverage5を100%にするために必要なテストケース数と同じです。循環的複雑度と同じく、
iffor,while(条件評価に関わらず)switch-caseの、breakを含むcase
によって各制御フロー6の経路数が決まります(ただし、三項演算子?:は制御フローを中断しないとみなす)。入れ子になっている場合は単純な経路数の和ですが、独立した制御フローが複数存在する場合はそれぞれの積を取ります。
例えば、以下の関数func()のパスの数は6です。
int func(){ if(A){ // この制御フローの経路数は2 // 処理 } if (B){ // この制御フローの経路数は3 while(C){ // 処理 } } return (a ? b : c); // no count // パスの数 = 2 * 3 = 6 }
パスの数の推奨値は80以下です。
独立したifの数だけ累乗で増えていくため、関数やコンポーネントの責務によっては巨大な数となることもありえます。組み込みでいうとハードに近い場所(どうしても物理的なレジスタ、カウンタ等の数だけ分岐させる必要が出る場合など)に大きくなりがち7で、そういった処理を下手に分割すると逆に凝集度が下がったりするのが悩みどころですが、基本的なビジネスロジックでは推奨値を超えることはないでしょう。
循環的複雑度が守れていれば違反することは少ないので、この指標の優先度は下がるかもしれません。
呼び出しレベルの数 (Number of Call Levels)
入れ子(ネスト)の最大深度です。(名前からはイメージしにくい。。)
if, for, while, switch-caseなどが対象。言われる前に視覚的にわかるので解消しましょう。この指標の推奨値は4以下です。
呼び出し元関数の数 (Number of Calling Functions)
対象の関数が、他のいくつの関数からコールされているかを表す指標です。ただし、一つの関数から複数回呼ばれた場合でも+1と数えます。
例えば以下の関数getVal()の呼び出し元関数の数は2です。
int getVal(){ return (a) } int func1(){ // +1 tmp = getVal(); aaa = getVal(); } int func2(){ // +1 tmp2 = getVal(); }
この指標の推奨値は5以下です。
普通に考えると「共通化してるんだから他関数から多数呼ばれるのは当然では?」となるわけで、この指標の真の目的が見えてきません。残念ながら(欧州系の規格ではありがちだけど)規格策定の背景や目的を解説している情報が見つからなかったため想像するしかないですが、Mathworks社のメトリクス説明には「より自己完結なコードでは上限値を守るべきである(https://jp.mathworks.com/help/bugfinder/ref/numberofcallingfunctions.html?lang=en)」と書かれており、この指標をあらゆる箇所に一律に適用するのは構造が複雑化・冗長化して嬉しくなさそうです。
またこの指標は関数単体というより、アーキテクチャに関する最適化を促すものとしても機能しそうです。うまく分離・共通化されたライブラリを使用するのはよいとしても、適切に階層化できていないとデバイスを直で操作するUtilityがそこかしこでコールされるようなことになり、その種の問題を定量的に示すことができます。ただその場合高い確率で修正困難だとは思うけど。説明・分析用にないよりマシってことかな…
呼び出された関数の数 (Number of Called Functions)
対象関数内で何種類別関数をコールしているかを表す指標です。わかりやすい。
例えば以下の関数funcの呼び出された関数の数は2です。
int hoge(); int fuga(); int func(){ return (hoge() + fuga()*hoge()) }
この指標の推奨値は7以下です。
これも呼び出し元関数の数と同じく、ソフト構造に由来する指標と言えます。新規で作る際に「何でも屋」みたいな関数・クラス設計はしないと思いますが、変更時にどれだけ階層化させるかの目安にはなりそうです。
non-OSなシステムでのmain関数(スケジューリングを行う部分)とかだと当然コールする関数が増えるので、適応する場合はアーキテクチャ設計を行ったうえで逸脱可能な関数を指定するのが良い運用だと思います。
関数パラメータの数 (Number of Function Parameters)
関数がとる引数の数です。以下の関数funcの関数パラメータの数は3です。
int func(int a, int b, char c)
この指標の推奨値は5以下です。
当然引数が多すぎると関数は複雑化していますが、Cで組む場合はグローバル変数とかポインタ経由すれば作り方次第でいくらでも入力を増やせる8ので、あくまで参考程度の指標でしょう。そのような作りを防ぐためにアーキテクチャ・設計パターンで縛った方がより効果的なので、他の指標よりは優先度低めかと思われます。
gotoステートメントの数 (Number of Goto Statements)
gotoの数です。この指標の推奨値は0です。
特に言うことはない。…と、片付けても良いですが、returnステートメントの数と合わせてまあまあ議論を呼びそうな指標です。
むやみやたらにgotoを使うべきではないのは自明ですが、gotoを使うと嬉しい場面もないことはないです。ぱっと思いつくのは
- 多重ループからの離脱
- early return(に準ずる処理)
ですね。前者は抜けようと思うとフラグを設けるか、あるいは関数化してearly returnさせるという方法になるでしょうか。後者も同様に、「関数の冒頭で、その後の処理について関心があるかどうか」を判定し、無関係な処理はskipするという使われ方が想定されます。このような場合に、goto (または early return)を許容しないと逆に関数が複雑化するという主張もできそうです。
これに対する明確な答えはないですが、そもそもこのルールが制定されている背景が構造化プログラミングから来ているとすると致し方ない面もあります。その辺の考察については以下が参考になりますね。
結局のところ、明確なbetterがない中では「何を優先するか」は設計者によってまちまちであり、設計を統一しないことによる品質低下を防ぐために当時主流であった「構造化プログラミング」の文脈で一つのルールを作った、という解釈に落ち着きそうです。特にほとんどが実績重視の派生開発となる車載事業では、ソフトウェアとしての寿命が長くなる傾向にあり、開発に携わる人の延べ人数が他業界と比較しても多くなると考えられるため、設計を一定のルールで縛るのは致し方なかったと思われます9。
現代的プログラミングを学んできた方々、「こんなやつらと仕事したくない」と罵倒するのをこらえてどうか優しい目で見守ってください。。
命令の (Number of Instructions)
関数内に含まれる命令の数についての指標です。
;で終わる文を1命令とする(空の場合はカウントしない)- 変数宣言は、初期化されている場合のみ1命令とカウントする
if,for,while,switch-case,break,returnなどの制御文は1命令とカウントする- ただし、
caseラベル自体はカウントしない
- ただし、
例えば、以下の関数func()の命令の数は8です。
int func(){ int i, j=0, k=0; // +2 for(i=0; i<10; i++){ // +1 if(j==1){ // +1 k++; // +1 }else if(j==2){ // +1 k--; // +1 }else{ // 直前のelse-ifとセットのためカウントしない ; // 空のためカウントしない } } return (k); // +1 }
この指標の推奨値は50以下です。
単純に命令が多いと関数がそれだけ縦に長くなるので、おのずと関数化したくなる気がします。1行1命令として、コメント抜きでだいたいフルHD1画面に収まる長さって感じかと(エディタやフォントサイズにもよりますが)。まとまっと初期化処理とかでもない限り実現できそうですね。「子関数化の目安」をわかりやすく定量化したものと言えそうです。
returnステートメントの数 (Number of Return Statements)
returnの数です。推奨値は1以下です。
gotoステートメントの数で述べた通り。平和にいこう()
言語スコープ (Language Scope)
少し特殊な指標です。
とし、(N1 + N2)/(n1 + n2)の値を言語スコープと呼びます。
例えば、以下の関数funcでは
int func(char i){ if (i == 0){ return i; }else{ return i * func(i-1); } }
- 出現した演算子の種類
n1は13int,(,),char,{,},if,==,return,;,else,*,-
- 出現したオペランドの種類
n2は4func,i,0,1
- 全ての識別子、オペランドを数えると、
N1 + N2= 32
よって、言語スコープは(23 + 9) / (13 + 4)より約1.88 となります。この指標の推奨値は4以下です。
かなり計算がめんどくさいので、実用的な関数に対して人力で求めるのは無理でしょう。この指標は「保守または変更にかかるコスト」を測定するものらしく、例えば
といった具合です。同一演算/同一オペランドを多数使用するということはある種の冗長さが含まれている可能性もあるため、処理や構造改善の気付きになるかもしれません。まあ設計段階でこの指標を測定できないので結局作ってから改善するしかないのですが10。そういう意味では微妙に役立ちにくそう。
終わりに
車載部品開発でよく用いられるコーディングメトリクスについて一通り書いてみました。当然ですがあくまで下流工程での指標であり、それより優先すべき設計思想やアーキテクチャ設計などがあればこの限りではありません。
あんまり他業界とか担当外製品のことはわかりませんが、これ全部守れてる or 妥当な逸脱理由を持っているってとこは流石に稀かと思います。結局はソフトウェアは常に陳腐化・レガシー化のリスクにさらされており、改善し続けるしかないのかもしれません。
次、元気があればMISRAとかにも触れたい。元気があれば。(保険かけとく)
-
車載ソフトウェアの品質保証を標準化するために設立された、ドイツの自動車メーカ5社からなる組織。↩
-
HISメトリクスが策定された背景も同じ理由です↩
-
みんな大好き『リーダブルコード』にあるとおり↩
-
マイヤーズインターバル(Myer’s Interval)、アキヤマ指標など。↩
-
ここでいう制御フローはif, for等の制御文により発生する
{}ブロックを指します↩ -
筆者の経験上の最大値は5億越えでした。南無。↩
-
組み込み用途ではスタック消費を抑えるために静的変数へのアクセスを多用する場合もある↩
-
当然「基準を見直せばいいじゃないか」と言いたくなりますがそこは実績重視の(ry↩
-
そして「現状正しく動いているコードを変更できない」呪いによってレガシー化していく↩
エンベデッドシステムスペシャリストに合格したので振り返り
題名の通り、エンベデッドシステムスペシャリスト(ES)に合格できたので軽く振り返ます。次に受ける人の参考程度になればよいかなと。(死ぬほどギリギリだったので偉そうなことは言えません)
ギリギリすぎて草
— じっく (@zickuuu) 2021年12月17日
まあ受かったからよし! pic.twitter.com/Aj4lOrjqyT
筆者スペック
- 工学部(電気系)
- 電気電子情報系を広く浅く(器用貧乏)
- 大学院で情報工学専攻に
- Computer Visionとか機械学習とかちょっとだけやったり
- 車載部品開発の会社に入社
- 研究内容と全く関係ない組み込みソフト開発に従事
まあよくある、就職に強いと聞いてとりあえず工学部に入ったけどフラフラしてた学生です。「電気とか制御とかあんまり興味ないなーとりあえず情報工学にしよっと」からのごりっごりにハード下回り、ベアメタルなソフト開発のお仕事してます。ぶっちゃけさっぱりわからんままモータ回してる。
新卒一年目の暇な時に応用情報は取得したため、広く浅い知識は持っている程度でした。午前I免除のボーナスタイムもありましたが、気づいたら期限切れてたので今回全部受け直した感じです。全体的にうっすら知ってはいるけど、組み込みの知識は少ないって状態でしたね。
学習時間
試験日(10月)の3ヶ月前くらいから勉強し始めました。午前問題は隙間時間にひたすらできるので、一日平均で30~60分程度やってた気がします。午後はまとまった時間が必要なので土日に一日2問ぐらい解こうと思ってやってましたが、結局トータル5,6問しか解かなかったような。。
一応仕事でやっている部分ではあるので、まっさらな状態からやるよりは少ない時間で済んだかもしれないです。
内容
出題範囲の要綱と過去問見ればなんとなくわかります。おわり。
にしてもよいですが、自分が受ける時はもう少し噛み砕いた説明があってほしかったので補足。一言で言うと、知識問題は午前まで、午後は基本的に時間との戦いです。
主に午前は(たぶん他試験も同様に)過去問をひたすら解いていればクリアできます。組み込み特有の知識(割り込み、レジスタ、スケジューリング、ページング、キャッシュetc)は午前IIで出るパターンがかなり限られており、5年分くらいやると大体覚えてくるかなと。午前Iを前提知識なしで受ける場合は6:4ぐらいで午前Iを優先すれば良いと思います。
午後は逆に知識をそれほど問われません。よく「国語の問題」と言われたりしますが、めちゃくちゃ頭の処理能力が高い人はノー勉でも受かるかもしれません。
国語の問題とはなんぞや、となるわけですが、問題文は主に
- とある組み込みシステムの概要
- システムを構成する各要素についての詳細な仕様
- (ソフト問題の場合)タスク構成、シーケンス図など
- (ハード問題の場合)回路構成、タイミングチャートなど
のような流れで説明されます。午後Iでは90分で2問、午後IIでは120分で1問解くわけですが、かなり時間ギリギリな作りになっています。ただ形式や回答パターンは決まっており、反復練習すれば解ける内容ではあるので、この辺りがセンター試験の国語を彷彿とさせるのでしょう。自分はそうだった。
とはいえ日本語の識字能力さえあれば解けるのか、と言われるともう一声ほしくて、例えば以下のようなことを気にしていると受かりやすいかもです。
- 単位系まで考慮して計算できるか
- degC→A→msのようにひとつずつ紐解いて計算する問題が多い
- 図を適切に読み解けるか
- 煩雑なシーケンス図で、関心のあるタスク同士のやりとりに注視したい
- 勝手に仕様を妄想せず、問題文から読み解けるか
- 「この場合はだいたいこうするだろ」→死
計算問題は複数の装置が絡んだ上で「どう言う値を設定しますか?」みたいに問われることが多いため、数字だけ追うと迷子になりやすいです。図を読み解くのは言わずもがなですが、日頃からよく触れている図だとスムーズに読み解けそうですね。あと最後のは割と重要ですが、基本問題文から類推できることしか回答になりません。変に知ったかぶると痛い目を見ます。
以上、自分が感じた要点でした。ソフトの問題しか見ていなかったのですが、終わってからハードの過去問少し見た感じだとソフトより情報量が少なそうに見えたので、「理系の素地があり、地頭がいい人」はハード問題の方が楽かもしれません。データリンク層あたりの通信の話とか出てきて、まあまあ面白そうだったのでちょっとぐらい取り組んでみたらよかったと今更になって思う。
次
ネスぺあたり受けてみようと思います。こっちはまじで全くの知識0から受けるので苦戦する予感しかしませんが・・・とりあえずやっていきます。
設計を知ることは原則を知ること。『プリンシプル オブ プログラミング』
久しくソフトウェア設計的な本に触れてなかったので、以下の本を読んでみました。

プリンシプル オブ プログラミング3年目までに身につけたい一生役立つ101の原理原則
- 作者:上田 勲
- 発売日: 2016/03/23
- メディア: 単行本
「3年目までに読んでおくべき」とありますが、具体的なコード例などはなく抽象度高めの話が続くのであまり経験のない新人がいきなり読んでもいまいちわからないかもです。むしろある程度手を動かした&アンチパターンを踏んだ経験のある人が読むことで、経験を体系的に整理する(原理原則として活用する)助けになる本です。
著者
上田勲氏が執筆されています。2020年2月時点でキャノンITソリューションズ株式会社にてアドバイザリーソフトウェアデベロップメントスペシャリスト(長い)として働いていたようです。検索すると登壇記事がヒットしたので、書籍と合わせて対外的な活動にも積極的な方なのかも。
概要
ソフトウェア開発現場で度々登場する設計指針や原則、思想、週間などを一つ一つトピックとして解説している本です。章立て毎に中身を一部抜粋したものは以下。
- 前提(すべてに共通する不変の真実)
- プログラムは本質的に複雑であり、常に改善し続ける必要がある
- コードこそがソフトの振る舞いを正確かつ完全に表現し、コードは設計書であることに留意する
- 原則(設計時のガイドライン)
- KISS(コードはシンプルに保つ)
- DRY(同じ処理を繰り返さない)
- YAGNI(変更は必要最小限に留める)
- PIE(コードに『意図』を埋め込む)
- SLAP(抽象化レベルを統一する)
- 思想(一貫したイデオロギー)
- 視点(コードの品質指標)
- 凝集度
- 結合度
- 直行性
- 習慣(良いとされる心構え)
- ボーイスカウトの規則(変更前よりもコードをきれいにしてから去る)
- エゴを捨ててプログラミングをする
- 手法(設計する上でのtips)
- 防御的プログラミング(想定内・想定外でエラーチェックを切り分ける)
- ラバーダッキング(話してみると考えがまとまる)
- 法則(アンチパターン)
- 割れた窓の法則(一部悪いコードがあると全体が悪化していく)
- ヤクの毛刈り(問題が芋づる式に発生した場合、早々に打ち切る or メモを取りながら順番に解決する)
101の原理原則とあるだけにすごく多い(UNIX思想・哲学で数稼ぎすぎだけど)ので、すべて取り上げることはできません。また互いに矛盾するような内容の原理もあるため、その時々で何を優先するかを決定しなければなりません。
よく言うSOLID原則はこの本には載ってませんでした。まあOCPとかポリシーと実装の分離とか、関連するような内容は含まれているのでこれを読んでから知識補間するのもよいかも。
実践
特にインパクトが強そうなものをピックアップし、実践します。自分の知識ドメインや設計経験が偏っているせいで、UNIX思想・哲学はピンとこないところが多かったので触れないことにします…そのうちわかるようになりたい。。
SLAP
「原則」の章はどれも重要なものですが、特にコードを読む上で重要なのはこれです。関数の抽象度レベルを揃え、処理の構造をわかりやすくする効果があります。詳細は以下サイトが参考になります。
SLAP実践の上では凝集度と照らしながらやるのがよさそうな気がします。何も考えず複合関数を列挙すると暗号的・論理的強度のような低凝集に嵌まりかねないので、意味や機能を意識したいところですね。
直行性
コード同士が独立性、分離性を持つように設計します。そのためにやるべきことはいくつかありますが、まず結合度が小さくなるように設計する必要があります。そのためには同一抽象度で機能をまとめたレイヤーを定め、厳格にそれを守った設計をすることです。
組み込みソフトウェアの設計では、マイコンのポート操作のような物理的な制御とアプリケーション毎のビジネスロジックでは抽象度が異なるため、レイヤー化のような手法は度々行われています。むしろハードやペリフェラルICが関わる分、具体→抽象のレイヤー化は他のソフトウェアより容易かもしれません。まあその分処理性能のとのトレードオフが出てくるため、組み込み開発は面倒なわけですが…
ボーイスカウトの規則
誰が名付けたんだって感じの規則ですが(笑)
ボーイスカウトが「来た時よりもきれいにして帰る」というのをもじって「変更する周辺の箇所が汚れていたらリファクタし、元の状態よりきれいにする」という心構えです。ボトムアップでコツコツ改善する方法なのでアーキテクチャや設計全体に大きく影響を与えることはないですが、チームのメンバーが全員これを徹底すればかなり改善効果が期待できます。別の法則として「割れた窓の法則」というのがありますが、継続的に改善することでメンバーの意識を高く維持できる(きれいな状態から汚すのは心理的ハードルが上がる)というメリットがあります。結局ソフトウェアは一人で作るものではないため、チーム全体に広く影響する原則は実践の費用対効果が高そう。
まとめ
ソフトウェアの設計原則に関する本を読みました。「プログラミング」と書かれていますが、さらに抽象度を高めるとエンジニアリング全般に通ずるような内容も多分に見受けられるので、設計者なら教養として読んでおくのもいいかも。